본격적 데이터 분석 실습에 앞서 파이썬 기초를 탄탄히 다졌던 1일차
필자는 1학년 2학기 전공기초로 수강한 '응용프로그래밍' 이후로 파이썬을 학습하거나 사용한 적이 없어
오늘 살펴보았던 파이썬 기초를 완벽히 알지 못했고,
이를 보완하기 위해 복습을 하게 되었다.

method split()은 괄호 안에 넣은 단위(반점이나 온점 등)를 기준으로 주어진 문자열을 슬라이싱하여 리스트로 반환한다
(깨알 개념: method는 . 뒤에 작성, 함수는 . 뒤가 아닌 앞에 (그 자체로) 사용한다.)
그런데 공백이 있는 경우 괄호 안에 공백 수만큼 넣어서 슬라이싱을 명령해야하는데, 매우 비효율적이므로
for loop과 method strip()을 이용하여 ','로 분리한 문자열을 반복적으로 공백 제거하여 리스트로 반환하는 방법을 사용할 수 있다. 여기서 중요한 것은 method strip()이 문자열의 처음과 끝, 양쪽으로부터 공백을 제거한다는 것이다.

method strip()에 대해 추가적인 학습을 진행하다보면 lstrip과 rstrip도 만날 수 있다.
lstrip은 왼쪽 단위 제거, 즉 왼쪽 정렬이고
rstrip은 오른쪽 단위 제거, 즉 오른쪽 정렬이다.
여기서 strip()의 괄호 안에 '#'과 같은 기호가 들어가게되면 이 기호를 단위로 삭제하게 된다.
(= 아무것도 없다면 공백을 뜻하므로 공백단위로 삭제 수행)

method join은 . 앞에 작성하는 ' ' 안에 있는 단위로 별개의 리스트를 merge하여 하나의 문자열로 반환한다.
파이썬의 가장 큰 장점은 method name이 상대적으로 직관적이라는 것이다.
method의 기능을 이해하고 이름과 연관지어 기억하기 참 좋은 언어인 것 같다.
추가적으로 method replace는 괄호 안에 있는 첫번째 단위(여기서는 온점)를 주어진 문자열에서 찾아 두번째 단위(여기서는 -)로 변경하여 문자열을 반환한다.

method find()는 괄호 안의 문자열을 찾는 함수로, 주어진 문자열에서 해당 문자열이 등장하는 첫번째 인덱스를 반환한다.더하여 해당 문자열이 없는 경우 -1을 반환한다.

method count()는 괄호 안에 있는 단위를 기준으로 해당 단위가 주어진 문자열에서 몇번 나오는지 그 값을 반환한다.
이와 비슷한 함수로는(method 아님 주의!!) len()이 있는데, 연계해서 기억할 것을 교수님께서 특히 강조하셨다.

함수 max와 min은 이름 그대로 뮨자열 내 유니코드 값이 가장 큰값과 작은 값을 반환한다.
이때 유니코드는 UTF-8과 같이 문자를 뜻하는데 그 '값'이므로 문자에 대응하는 값, 즉 숫자를 뜻한다.
이를 함수 ord()로 연산 및 반환할 수 있으며, 함수 chr()를 이용해 유니코드 값에 대응하는 문자를 반환한다.

import string
src_str=string.ascii_uppercase # ABCDEFGHIJKLMNOPQRSTUVWXYZ
dst_str=src_str[3:]+src_str[:3] # DEFGHIJKLMNOPQRSTUVWXYZABC
# 함수 만들기
def ciper(a):
idx=src_str.index(a) # 입력된 문자의 대문자 알파벳 순 문자열에서의 인덱스 찾기
return dst_str[idx] # 암호화를 위해 변주를 준 문자열에서 위에서 찾은 인덱스를 가진 문자 반환(암호화)
src = input('문장을 입력하시오: ')
print('암호화된 문장 : ', end='') # end='' 줄바꾸지 않겠다
for ch in src:
if ch in src_str: # 비교를 위해 이 케이스에서는 입력되는 문자는 대문자로 구성되어야 함
print(ciper(ch), end='')
else:
print(ch, end='') # 대문자 알파벳 순 문자열에 해당 문자가 없는 경우 해당 문자 그대로 반환(암호화x)
print()

method count와 함수 len이 비슷한 이유. 이렇게 갯수를 세는데에 len을 사용할 수 있기 때문이다.


문제 힌트만 보고 직접 짜본 코드! 여기서 기억하고 싶은 것은 python print 방식이다.
문자와 숫자 자료형 변수를 함께 출력하고 싶을 때, print(f"문자 {숫자자료형변수}") 의 형태로 사용한다는 것!
잊지말고 자주 써서 익혀보자 ㅎㅎ
(+) python 문법에는 count++ 사용 시 에러가 발생한다. count+=1 을 쓰도록!


여기서 기억하고 싶은 것은 함수 str()! 문자열로 변환한다는 것이다.
따라서 문자열 변수 otp에는 n_digits 만큼 랜덤하게 할당된 문자변수가 할당될 수 있는 것이다.
pip install pandas matplotlib wikipedia wordcloud
코랩이든 cmd든 주피터 노트북이든
워드 클라우드(단어의 크기로 단어의 빈도 및 중요성 시각화)를 구현하기 위해서
pip install 명령어 입력이 필요하다.
import wikipedia
# 위키피디아도 모듈로 설치 가능
import matplotlib.pyplot as plt
wiki = wikipedia.page('Artificial intelligence')
# 위키백과 사전의 컨텐츠 제목 명시
text = wiki.content
# 페이지의 텍스트 컨텐츠 추출
from wordcloud import WordCloud
wordcloud = WordCloud(width=2000, height=1500).generate(text)
# 워드 클라우드 생성
# text를 보여줄 이미지 크기 세팅
plt.figure(figsize=(40,30))
# 화면에 워드 클라우드 이미지 그리기
plt.imshow(wordcloud)
# 이미지 그리기 함수 = imshow()
plt.show()
위키피디아에서 특정 제목을 가진 주제에 대한 내용을 워드 클라우드로 나타낸 결과물이다!
시각적으로 확인가능한 결과물이 있으니 코드의 동작이 더욱 와닿는다.

파이썬에서 다루는 정규식을 사용하기 위해 re 모듈을 이용해야 한다.
(+) 막간 깨알개념: 인스턴스= 객체가 프로그램에서 동작 가능한 상태 / 객체= 클래스로 만들 수 있는, object

여기 두 실행 코드에서 주목할 점은 생각보다 꽤 많은데 우선 짚어보자면
1. group화
2. meta character(메타문자)
3. method findall()
이렇게 세가지다.
1. 먼저 그룹을 생성하는 방법으로 위 5번째 코드와 같이 compile 안에 (), () 묶음 구분으로 그룹을 분류할 수 있다.
이때 여기서 적용된 인자들(\d와 같은 부분)을 메타 문자로 보고 우리는 메타 문자에 대해 알아둘 필요가 있다.
2.


이런 메타문자의 인자 형태는 기존에 익숙하게 사용하던 C, JAVA와는 사뭇 달라 익혀둘 필요가 있다.
파이썬은 대소문자의 영향을 크게 받는 만큼 \s, \S의 의미가 다른 것 또한 인상적이다.
특히 두번째 사진은 [] 나 \자료형 뒤에 오는 {n}의 n이 찾고자 하는 문자의 갯수라는 것을 기억하자.

파이썬만의 독특한 메타문자 특징은 이렇게 적용하여 살펴볼 수 있다.

더하여 이러한 메타문자의 가장 중요한 요소 두가지는 점과 별표다.
점: 모든 문자에 대하여 ok

이런식으로 점의 갯수에만 충족한다면 어떤 문자가 와도 만족한다고 판단함
별표: 해당 문자가 몇번 반복되어도 ok

이런식으로 별표의 대상(여기서는 B네요)이 몇번 반복되어도(심지어 0번 반복되어도) 만족한다고 판단함

물음표 또한 메타문자 탐색에 사용된다.
가령 AB?라고 한다면 A 혹은 AB를 포함한 문자열에 대해 만족한다고 판단하는 최소 매칭을 찾는다.
3. 마지막 method findall(' ', 문자열)을 살펴보자.

method findall(' ', 주어진 문자열)은 주어진 문자열에 해당하는 ' '를 찾아 해당 문자열을 모두 반환한다.
위 예제에서는 My or my를 해당 문자열로 설정하여 최소 매칭을 찾아 모두 반환하고 있다.

이러한 메타 문자를 활용하기 위해서는 어떤 기준으로 문자열(작은 범위의 글)을 나누고 찾을 것인지가 중요하다.
위 예제에서는 1. 숫자가 등장하면 문장의 단위를 나누고 2. 나눠진 문장의 첫 말에는 각각의 숫자 번호를 가지며 3. 문장을 분리한 이후에는 rstrip()을 활용하여 오른쪽 정렬을 실행하고자 한다.

따라서 코드에서는 '^(문자열 시작)\([0-9](0부터 9까지 중 하나의 수)+(한자리 수 이상도 가능=즉, 숫자를 가지고 있다면 가능)\)' 형태의 메타문자를 활용한 search를 구현하여 원하는 결과값을 도춣할 수 있다.
이걸 분석하면서 아직은 메타문자표를 계속 봐야하는데, 익히는 것이 중요하겠다는 생각이 든다.

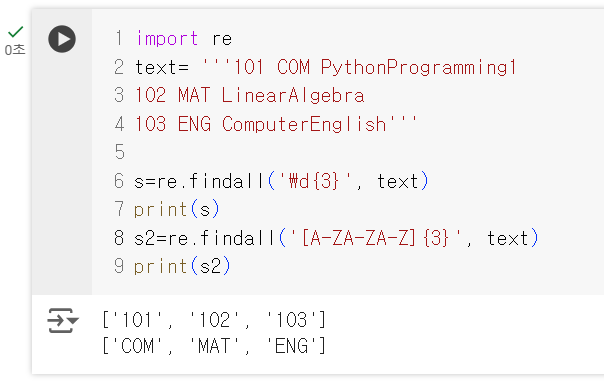
다음과 같이 학사 코드가 주어져있을때, '[수강번호] [수강코드] [과목이름]'
수강 번호만 출력하기 위해서는 아래와 같은 코드를 이용할 수 있다.

역시나 메타문자를 사용한 것인데,
숫자로 이루어진 부분이 공교롭게도 수강번호에만 있으므로 \d+ 로 search가 가능하다.

그러나 이러한 도전문제를 만났을 떼 코드는 달라져야만 한다.
1)에 기존에 작성한 코드를 그대로 적용한다면 Python Part1에 포함되어 있는 1이 같이 출력되기 때문이다.
따라서 그때 지정해야하는 것이 메타문자 \d+가 아닌 \d{3}이다.
+를 사용하면 뒤에 몇자리의 숫자가 오든 만족하지만, 여기서는 세자리로만 이루어진 수강번호를 출력하고 싶은 것이기 때문에 자릿수 지정, 즉 {3}을 사용하여 수강번호만 출력이 가능하다.
2)에서도 마찬가지로 수강코드만을 출력하고자 하는 상황이기 때문에, 숫자 \d 대신 알파벳만을 지칭하는 [A-Z A-Z A-Z ]{3} 를 활용하여 수강코드만 출력이 가능하다.
이때 \s, \S를 사용하지 않는 이유는 s는 알파벳과 숫자를 모두 포함하기 때문에 수강코드만 출력하는데 적합하지 않다.

문자열에 이메일 주소가 포함된 문장이 주어질 때 이메일 주소만 추출하고자 하는 문제가 있다.

여지껏 자주 등장한 method findall()을 이용하면 원하는 메일 주소만 리스트 형태로 모두 반환 가능하다.

여기서 등장한 도전문제! 사실 이 도전문제를 풀고 이해하는 과정이 사용한 개념을 익히는데 도움이 되는 것 같다.
이 도전문제에서는 추출한 이메일을 한번 더 분리하여 출력하는 코드를 만들어야 한다.

먼저 나는 method findall()을 이용해 이메일만 1차적으로 추출했다. 여기까지는 기본 lab 코드와 동일하다.
그 다음으로는 group 예제를 풀때 사용했던 method compile을 이용해 그룹을 나눌 기준을 괄호로 표시하여 아이디와 도메인을 분류하는 명령어를 작성했다. 이때 findall()을 통해 추출한 이메일이 여러 개이기 때문에 for loop을 이용하여 모든 이메일이 compile에 의해 분류될 수 있도록(그룹화될 수 있도록) 구현하여 abc@fackbook.com과 bbc@google.com 모두 아이디와 도메인이 분리될 수 있도록 코드를 구현했다.
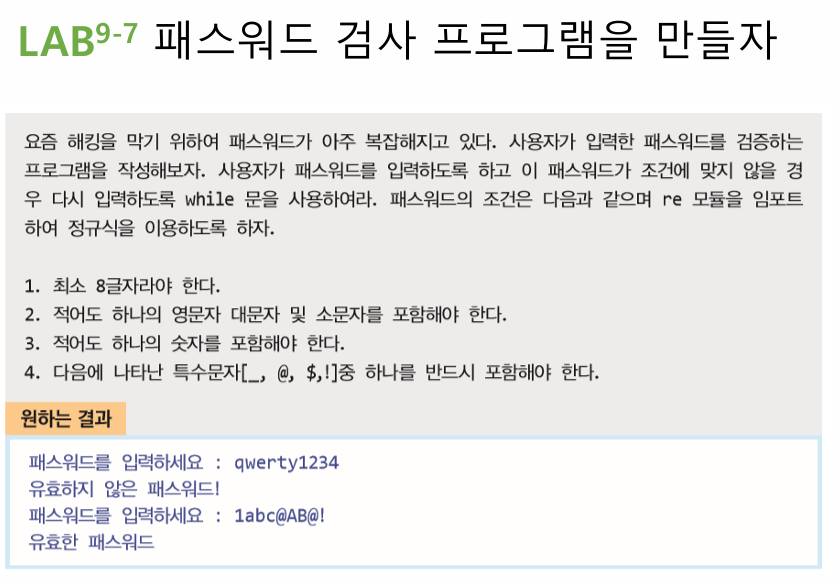
여기 4개의 조건을 충족할 때 패스워드로 등록할 수 있는 프로그램이 있다.
이 4가지 조건은 if statement로, 패스워드가 등록될 때까지는 while loop로 무한 반복하는 코드를 만들면

이런 식으로 if statement의 조건이 충족하지 않아 else로 이동하여 break를 만나 무한 반복 while loop가 종료되는 코드로
원하는 형식의 패스워드를 찾으면 종료되면 프로그램을 구현할 수 있다.

method sub()를 이용해서 특정 문자열에 대해 다른 문자열로 바꿔서 지정하는 코드도 구현이 가능하다.


이러한 method sub()를 이용해 hash function을 구현할 수 있다.
여기서는 2, 7, 99를 가져와 해시 함수에 넣은 후 값을 변환하여 출력하는 코드인데, hash에 입력되는 문자열 m을 숫자형으로 변환하여(계산하기 위해) 해시 함수 연산 이후 다시 문자열로 변환하는 부분에 주목할 필요가 있다.
이는 method sub()가 특정 문자열에 대해 다른 '문자열'로 대체한다는 특징을 가지기 때문이다.
method sub()는 문자열에서 불필요하다고 생각되는 부분, 불용어를 삭제하는데도 사용할 수 있다.

다음과 같이 특정 메세지에서 지우고 싶은 부분이 있을 때,
이를 sub()로 지운 후 출력하는 코드를 작성해보자.

이런 식으로 sub()를 사용할 때,
1) 삭제하고자 하는 부분을 첫번째에 작성,
2) 그 이후에 대체할 문자열에 ''(공백)을 작성,
3) 마지막으로 해당 문자열을 찾을 대상 문자열을 작성하여 삭제(대체)가 가능하다.
이런식으로 파이썬에는 searh(), findall(), sub() 등의 검색하는 함수를 포함하는 정규식이 존재한다.
정규식은 특정한 규칙을 가진 문자열의 집합을 표현하는데 매우 유용한 형식언어이자,
정규식은 텍스트 데이터(많은 사람이 읽고 이해할 수 있는 데이터)를 다루는데 유용한 도구이며,
정규식을 이용하여 문자열의 검색과 대치를 패턴형식으로 수행할 수 있다.
'studylog' 카테고리의 다른 글
| 240625 가천대 DNA School 헬스케어 파이썬 분석 실무 3일차 (0) | 2024.07.01 |
|---|---|
| 240625 가천대 DNA School 헬스케어 파이썬 분석 실무 2일차 (0) | 2024.07.01 |
| ~240502 백준 review - [입출력과 사칙연산] (0) | 2024.05.02 |
| 240419 백준1008번 A/B (0) | 2024.04.19 |
| 231020 TIL (0) | 2023.10.20 |



